The value of pi can be approximated by Monte Carlo method. This can easily be done with any thing from a programmable calculator like the Nspire, or much more efficiently in parallel computing devices like GPU.
Writing code in the Nspire is straight forward. Nspire Basic provided random number functions like RandSeed(), Rand(), RandBin(), RandNorm() etc.
To implement the Monte Carlo method in GPU, random numbers are not generated in the CUDA kernel functions, but in the main program using CuRand host APIs. On the NVIDIA GPU, CuRand is an API for random number generation, with 9 different types of random number generators available. At first I picked one from the Mersenne Twister family (CURAND_RNG_PSEUDO_MT19937) as the generator but unfortunately this returned a segmentation fault. Tracing the call to curandCreateGenerator revealed the status value returned is 204 which means CURAND_STATUS_ARCH_MISMATCH. It turns out this particular generator is supported only on Host API and architecture sm_35 or above. Eventually settled with CURAND_RNG_PSEUDO_MTGP32. The performance of this RNG is closely tied to the thread and block count, and the most efficient use is to generate a multiple of 16384 samples (64 blocks × 256 threads).
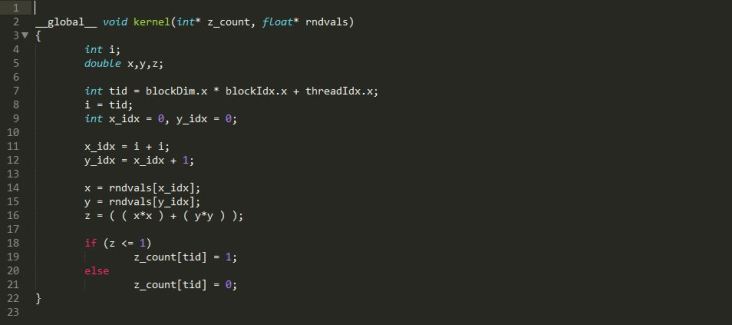
On a side note, to use the CuRand APIs in Visual Studio, the CuRand library must be added to the project dependencies manually. Otherwise there will be error in the linking stage since the CuRand is dynamically linked.

On the Nspire, using 100,000 samples, it took an overclocked CX CAS 790 seconds to complete the simulation. The same Nspire program finishes in 8 seconds in the PC version running on a Core i5.
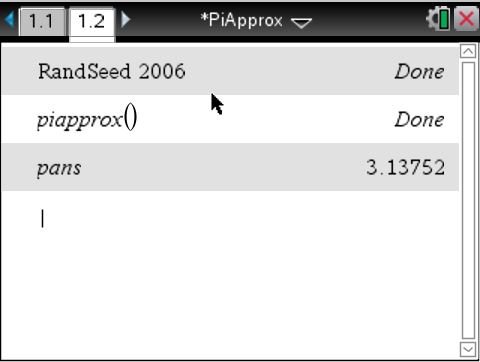
On the GPU side, CUDA on a GeForce 610M finished in a blink of an eye for the same number of iterations.
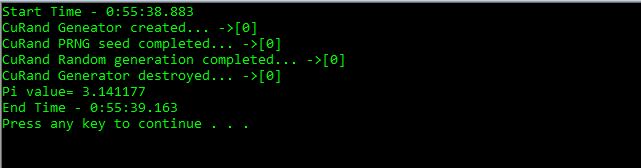
To get a better measurement on the performance, the number of iteration is increased to 10,000,000 and the result on performance is compared to a separately coded Monte Carlo program for the same purpose that run serially instead of parallel CUDA. The GPU version took 296 ms, while the plain vanilla C ran for 1014 ms.